监督学习一直处于研究的前沿 计算机视觉 以及过去十年的深度学习.
在监督学习环境中,需要人工对大量数据集进行标注. 然后, models use this data to learn complex underlying relationships between the data and label and develop the capability to predict the label, 根据数据. 深度学习模型通常需要大量数据,需要大量数据集才能实现良好的性能. Ever-improving hardware and the availability of large human-labeled datasets has been the reason for the recent successes of deep learning.
One major drawback of supervised deep learning is that it relies on the presence of an extensive amount of human-labeled datasets for training. This luxury is not available across all domains as it might be logistically difficult and very expensive to get huge datasets annotated by professionals. 虽然获取标记数据可能是一项具有挑战性且成本高昂的工作, 我们通常可以访问大量未标记的数据集, 尤其是图像和文本数据. 因此,我们需要找到一种方法来挖掘这些未被充分利用的数据集,并将它们用于学习.
在没有大量标记数据的情况下,我们通常使用 转移学习. 什么是迁移学习?
迁移学习是指使用从类似任务中获得的知识来解决手头的问题. 在实践中, 这通常意味着使用从类似任务中学习到的深度神经网络权重作为初始化, 而不是从随机初始化权重开始, 然后在可用的标记数据上进一步训练模型来解决手头的任务.
迁移学习使我们能够在小到几千个例子的数据集上训练模型, 它可以提供非常好的性能. 预训练模型的迁移学习可以通过三种方式进行:
通常, 神经网络的最后一层进行最抽象和特定任务的计算, 哪些通常不容易转移到其他任务. 相比之下, 网络的初始层学习一些基本特征,如边缘和常见形状, 哪些是容易在任务间转移的.
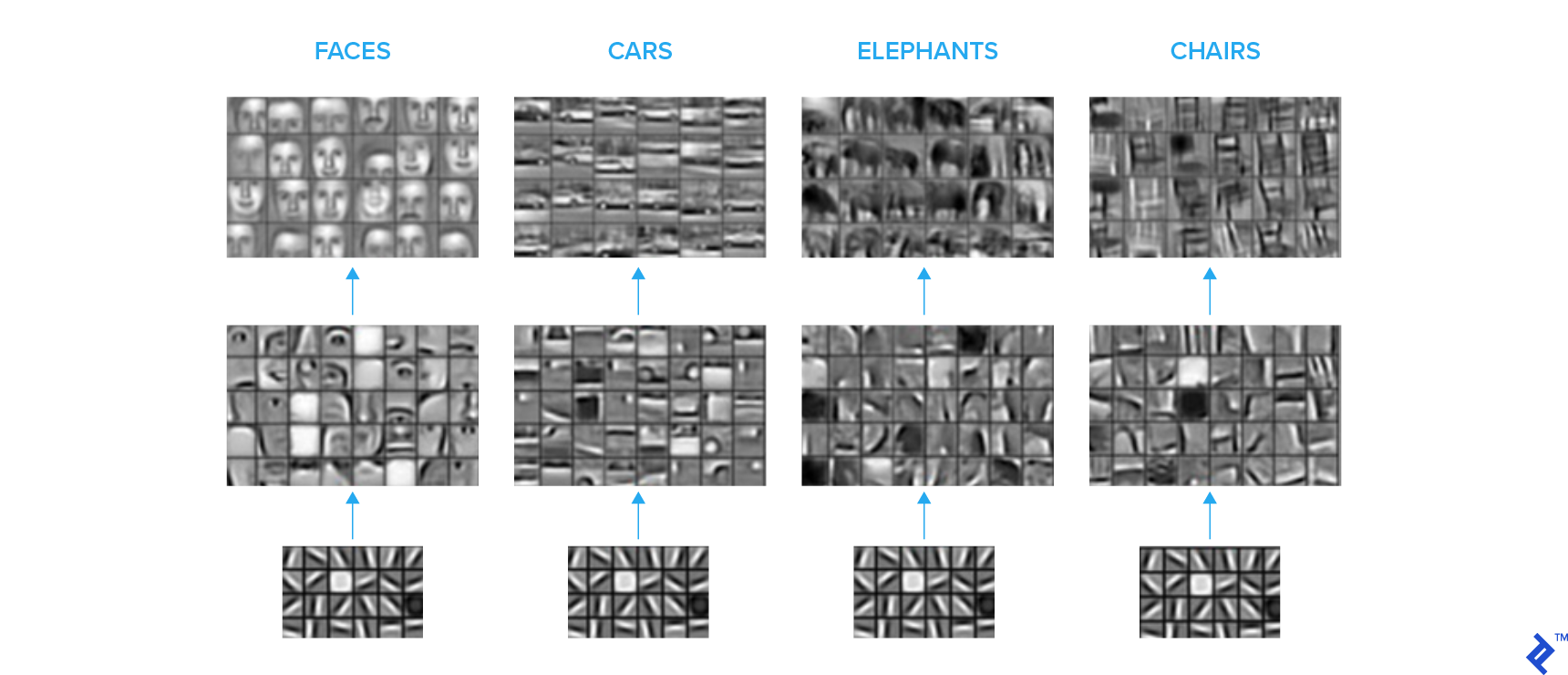
The image sets below depict what the convolution kernels at different levels in a convolutional neural network (CNN) are essentially learning. 我们看到一个分层表示, 初始层学习基本形状, 并逐步, 更高层学习更复杂的语义概念.
一种常见的做法是在大型标记图像数据集(如 ImageNet),并在最后切掉完全连接的层. 新, 然后根据所需的类数量附加和配置完全连接的层. 转移的层被冻结, 新的层是在你的任务中可用的标记数据上训练的.
在这个设置中, 预训练模型被用作特征提取器, 顶部的完全连接层可以被认为是一个浅分类器. 这种设置比过拟合更健壮,因为可训练参数的数量相对较少, 因此,当可用的标记数据非常稀缺时,这种配置可以很好地工作. 多大的数据集才算非常小的数据集,这通常是一个需要多方面考虑的棘手问题, 包括手头的问题和模型主干的大小. 粗略地说,对于由几千张图像组成的数据集,我会使用这种策略.
另外, 我们可以从一个预训练的网络中转移这些层,并在可用的标记数据上训练整个网络. This setup needs a little more labeled data because you are training the entire network and hence a large number of parameters. 当数据稀缺时,这种设置更容易出现过拟合.
这种方法是我个人最喜欢的,通常会产生最好的结果,至少在我的经验中是这样. 在这里, we train the newly attached layers while freezing the transferred layers for a few epochs before fine-tuning the entire network.
微调 the entire network without giving a few epochs to the final layers can result in the propagation of harmful gradients from randomly initialized layers to the base network. 此外, 微调需要相对较小的学习率, 两阶段方法是一个方便的解决方案.
This usually works very well for most image classification tasks because we have huge image datasets like ImageNet that cover a good portion of possible image space—and usually, 从中学习的权重可以转移到自定义图像分类任务中. 此外,预训练的网络是现成的,从而促进了这一过程.
然而, this approach will not work well if the distribution of images in your task is drastically different from the images that the base network was trained on. 例如, 如果您正在处理由医疗成像设备生成的灰度图像, 转移学习 from ImageNet weights will not be that effective and you will need more than a couple of thousand labeled images for training your network to satisfactory performance.
相反,针对您的问题,您可以访问大量未标记的数据集. 这就是为什么从未标记的数据集中学习的能力是至关重要的. 另外, 未标记的数据集通常比最大的标记数据集在种类和数量上都要大得多.
在像ImageNet这样的大型基准测试中,半监督方法已经显示出优于监督方法的性能. Yann LeCun很有名 蛋糕的类比 强调无监督学习的重要性:
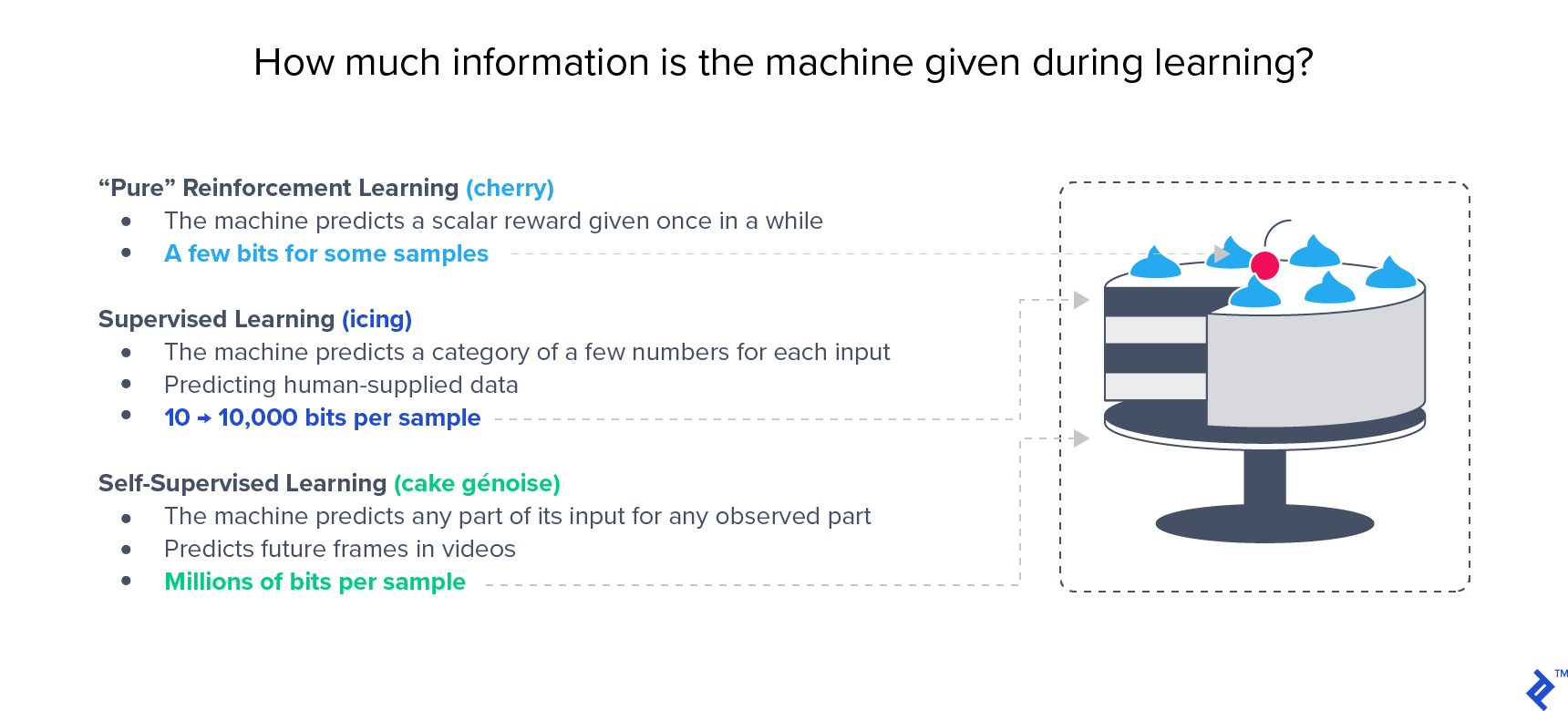
这种方法利用标记和未标记的数据进行学习, 因此它被称为半监督学习. 当您有少量标记数据和大量未标记数据时,这通常是首选的方法. 有些技术可以让你同时从标记和未标记的数据中学习, 但我们将在两阶段方法的背景下讨论这个问题:对未标记数据的无监督学习, 迁移学习使用上面描述的策略之一来解决你的分类任务.
在这些情况下,无监督学习是一个相当令人困惑的术语. These approaches are not truly unsupervised in the sense that there is a supervision signal that guides the learning of weights, 而监控信号则来源于数据本身. 因此, it is sometimes referred to as self-supervised learning but these terms have been used interchangeably in literature to refer to the same approach.
自监督学习的主要技术可以根据它们如何从数据中生成监督信号来划分, 如下所述.
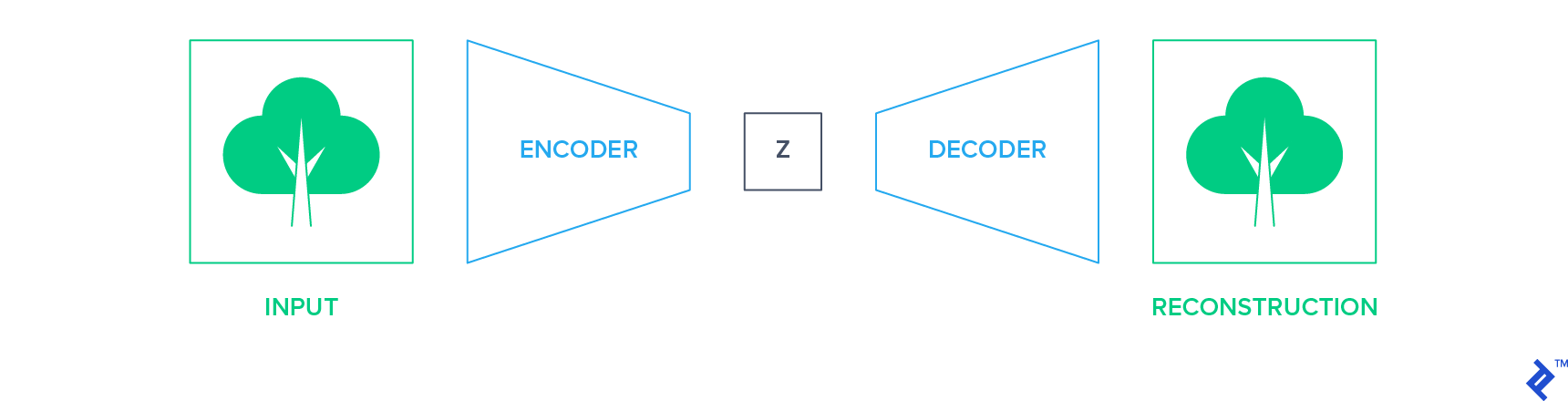
生成方法的目的是在数据通过瓶颈后精确地重建数据. 这种网络的一个例子是自动编码器. They reduce the input into a low-dimensional representation space using an encoder network and reconstruct the image using the decoder network.
在这种设置中,输入本身成为训练网络的监督信号(标签). 然后可以提取编码器网络并将其用作构建分类器的起点, 使用上述部分讨论的迁移学习技术之一.
同样,另一种形式的生成网络 生成对抗网络 (gan) -可用于未标记数据的预训练. 然后,可以采用鉴别器并对分类任务进行进一步微调.
判别方法训练神经网络学习辅助分类任务. 选择一个辅助任务,使监督信号可以从数据本身派生出来, 无需人工注释.
这类任务的例子是学习图像补丁的相对位置, 对灰度图像进行着色, 或者学习应用在图像上的几何变换. 我们将进一步详细讨论其中的两个.
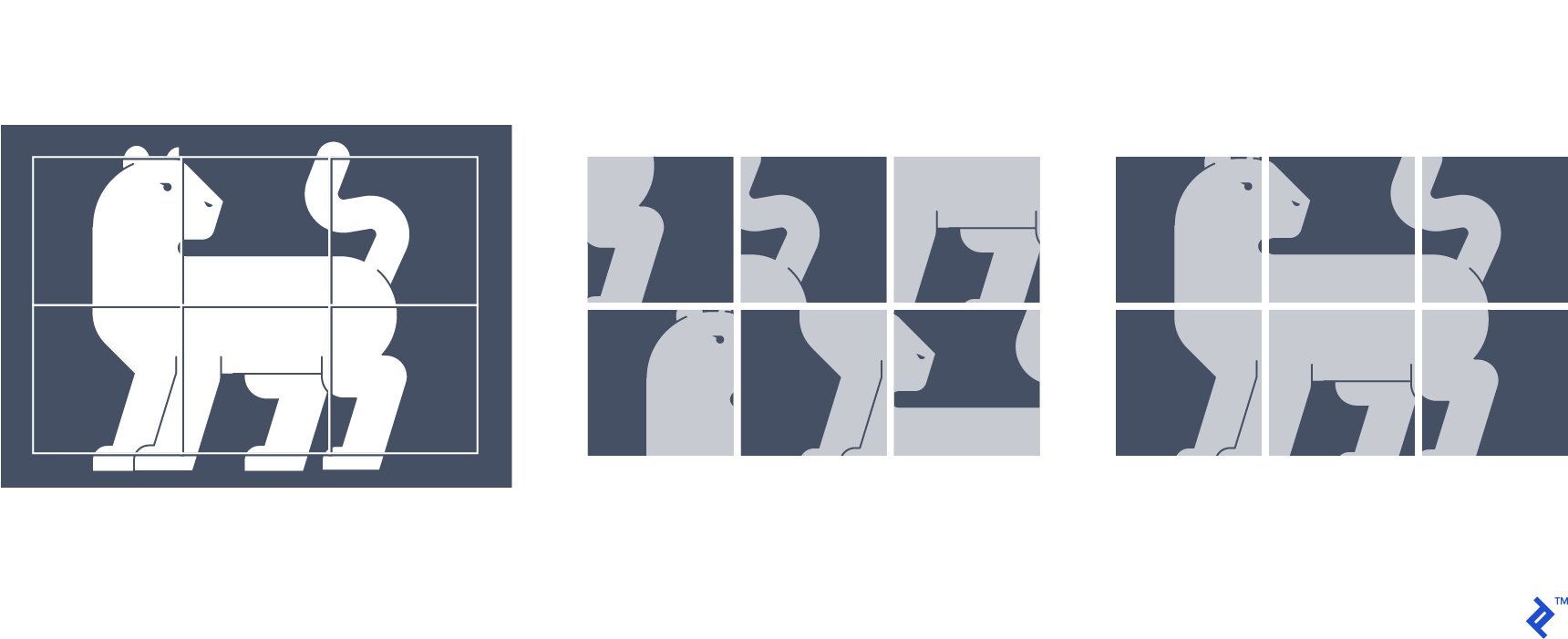
在这个技术中, 从源图像中提取图像补丁,形成类似拼图的网格. 路径位置被洗牌, 洗牌后的输入被输入到网络中, 哪一个经过训练可以正确地预测网格中每个补丁的位置. 因此,监督信号就是每条路径在网格中的实际位置.
在学习中, the network learns the relative structure and orientation of objects as well as the continuity of low-level visual features like color. The results show that the features learned by solving this jigsaw puzzle are highly transferable to tasks like image classification and object detection.
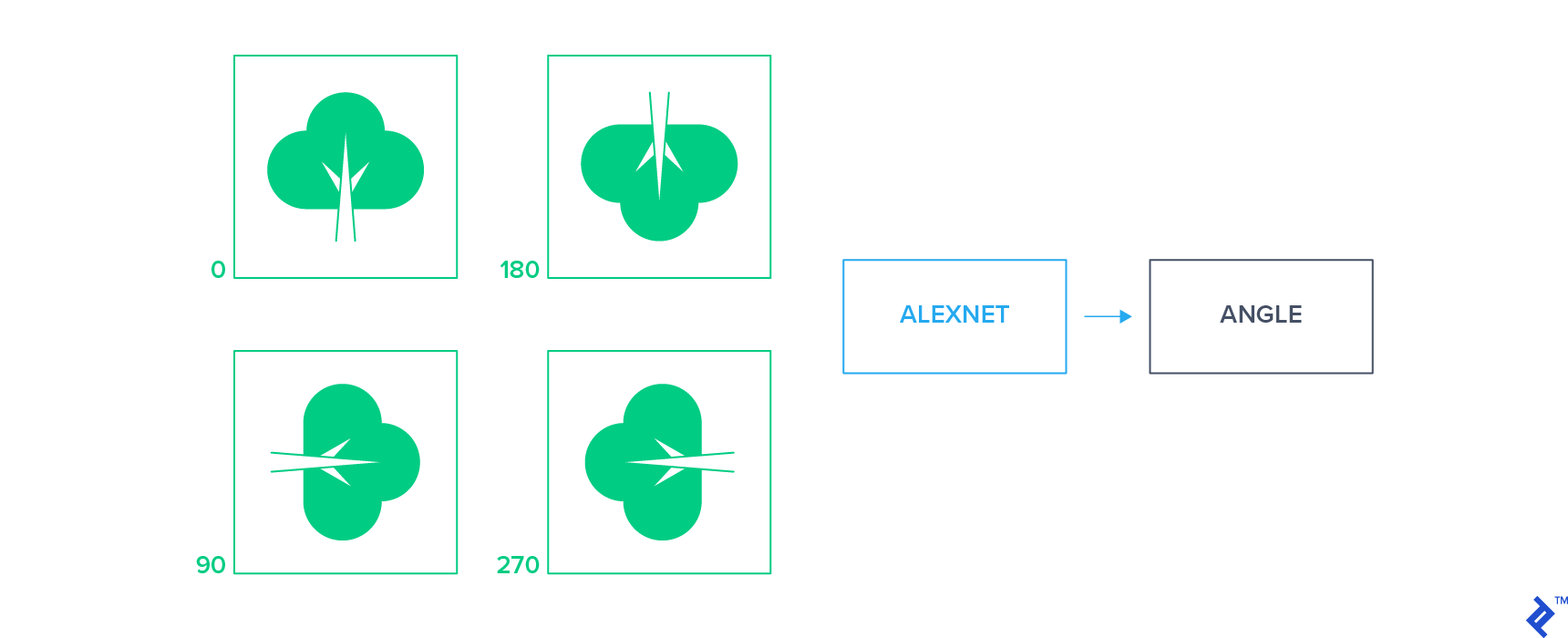
These approaches apply a small set of geometric transformations to the input images and train a classifier to predict the applied transformation by looking at the transformed image alone. One example of these approaches is to apply a 2D rotation to the unlabeled images to obtain a set of rotated images and then train the network to predict the rotation of each image.
This simple supervision signal forces the network to learn to localize the objects in an image and understand their orientation. Features learned by these approaches have proven to be highly transferable and yield state of the art performance for classification tasks in semi-supervised settings.
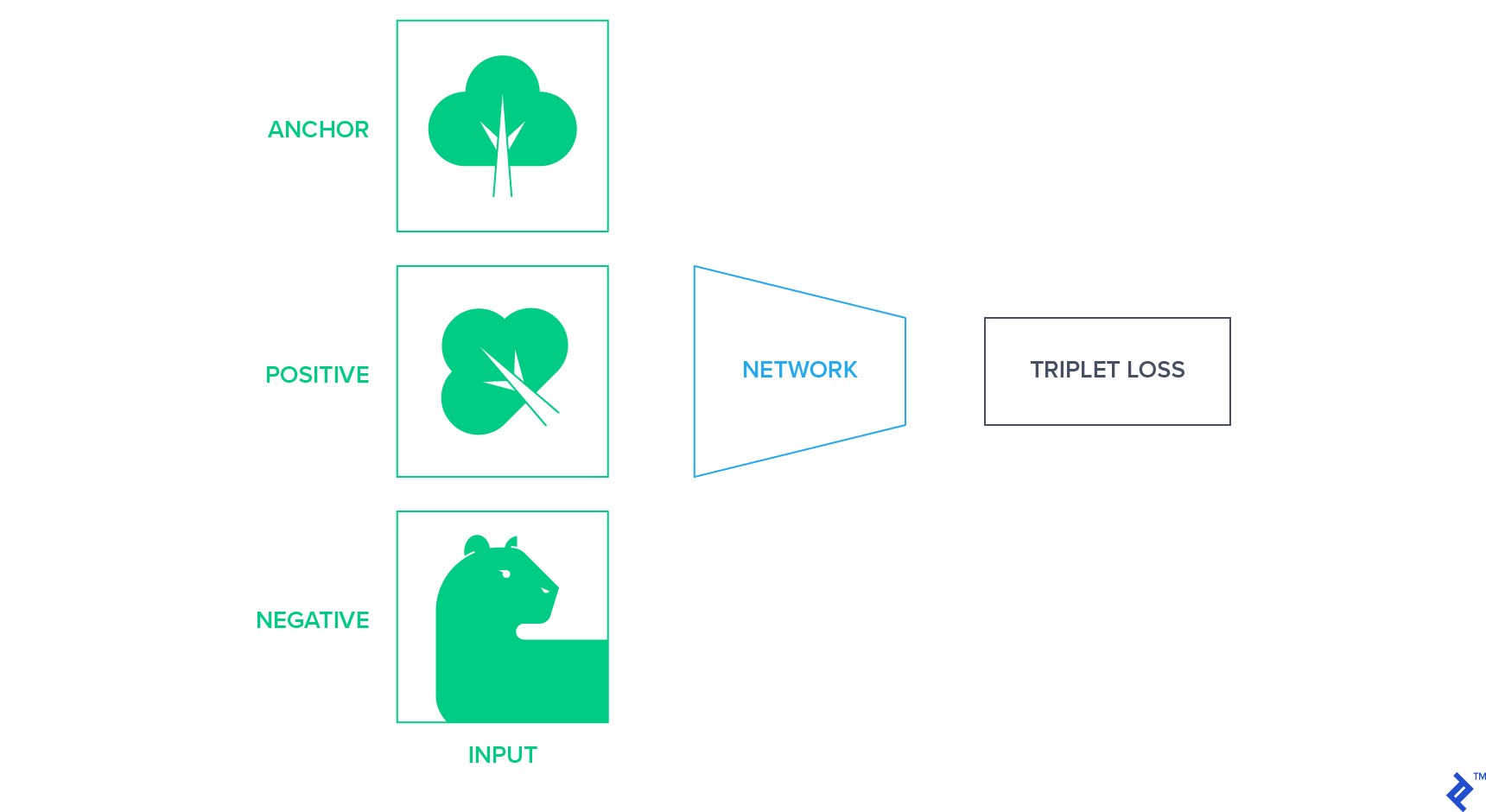
These approaches project the images into a fixed-sized representation space where similar images are closer together and different images are further apart. 实现这一点的一种方法是使用 暹罗网络 基于三联体损失,最小化语义相似图像之间的距离. 三重损失需要一个锚, 一个积极的例子, and a negative example and tries to bring positive closer to the anchor than negative in terms of Euclidean distance in latent space. Anchor和positive是同班同学, 负例是从剩下的类中随机选择的.
在未标记数据中, we need to come up with a strategy to produce this triplet of anchor positive and negative examples without knowing the classes of images. One way to do so is to use a random affine transformation of the anchor image as 一个积极的例子 and randomly select another image as a negative example.
在本节中, 我将涉及一个实验,从经验上建立了图像分类的无监督预训练的潜力. 这是我的学期课题 深度学习课程 我去年春天在纽约大学和Yann LeCun一起做的.
我们训练了7个模型,每个模型在每个类中使用不同数量的标记训练样本. 这样做是为了了解训练数据的大小如何影响我们的半监督设置的性能.
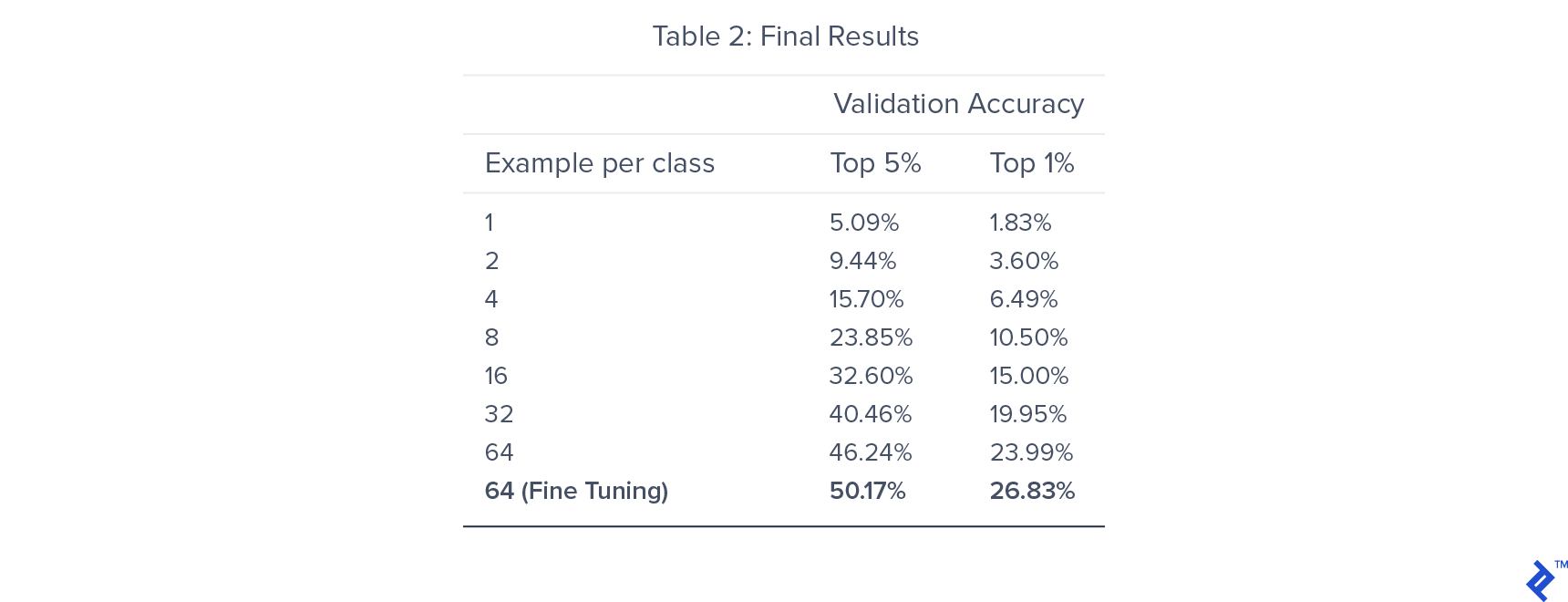
我们能够在旋转分类的预训练中获得82%的准确率. 对于分类器训练,前5%的准确率在46附近饱和.24%,对整个网络进行微调,最终得出的数字是50.17%. 通过利用预训练, 我们得到了比监督训练更好的效果, 哪个给出了前5名40%的准确率.
正如预期的那样,验证精度随着标记训练数据的减少而降低. 然而, 在有监督的环境下,性能的下降并不像人们所期望的那样显著. A 50% decrease in training data from 64 examples per class to 32 examples per class only results in a 15% decrease in the validation accuracy.
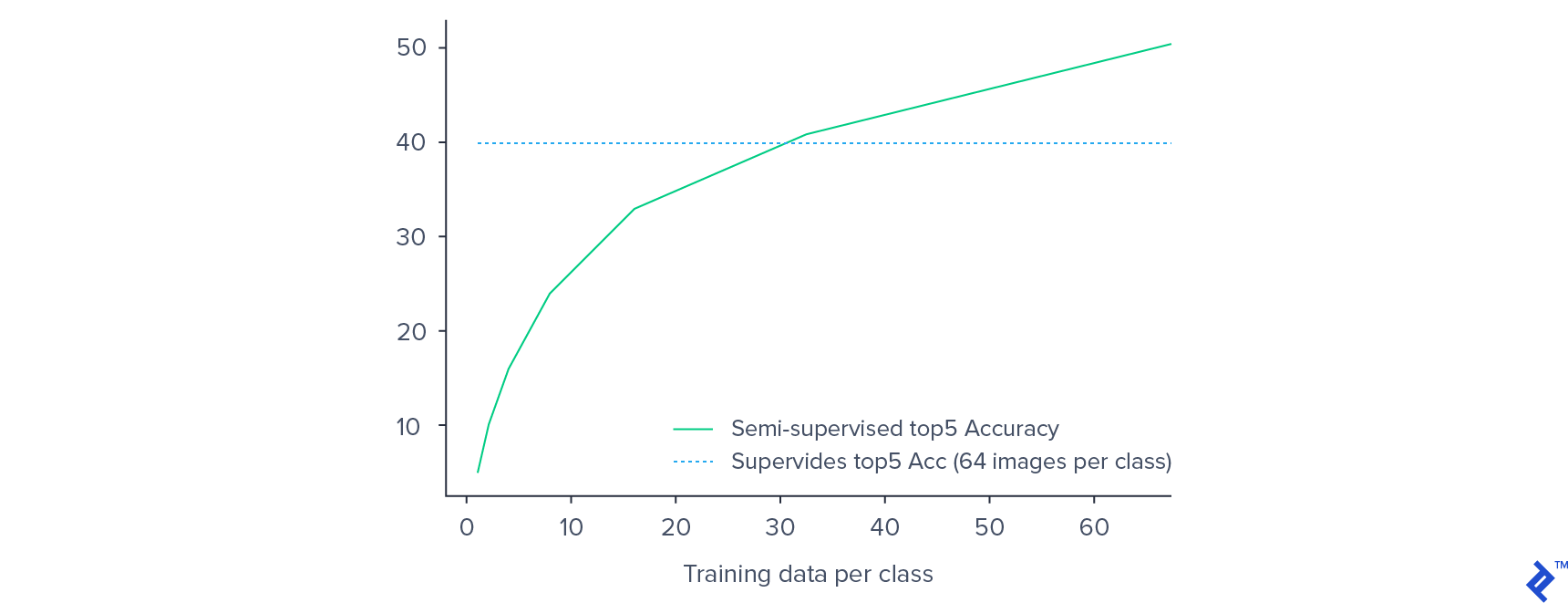
每个类只使用32个示例, 我们的半监督模型比每个类使用64个样本训练的监督模型具有更好的性能. This provides empirical evidence of the potential of semi-supervised approaches for image classification on low-resource labeled datasets.
We can conclude that unsupervised learning is a powerful paradigm that has the capability to boost performance for low-resource datasets. Unsupervised learning is currently in its infancy but will gradually expand its share in the 计算机视觉 space by enabling learning from cheap and easily accessible unlabeled data.
在有监督的学习环境中, 模型同时提供数据和标签, 哪个通常是手动注释的. 然后,模型学习将数据映射到标签的函数,从而开发预测标签的能力, 根据数据.
有监督机器学习的两大类是分类和回归. 回归试图将输入数据映射为连续变量, 而分类则将输入映射到一个离散变量.
在监督学习中, 我们已经标记了对学习至关重要的数据, 在无监督学习中, 我们不需要提供标签.
深度学习本质上是机器学习的一个子集, 所以监督学习的定义是一样的.
监督图像分类将图像映射到为它们提供的标签. Unsupervised image classification involves the separation of images into groups based on intrinsic similarities and differences between them, 没有任何标记数据.
世界级的文章,每周发一次.
世界级的文章,每周发一次.

